
前言
针对于秒杀场景来说,流量往往在一个特定时间点有个高度集中的流量洪峰,这个瞬时对于资源的消耗是很大的,这时往往对于服务的稳定性带来了极大的挑战,如果按照流量洪峰预估系统资源,则可能存在极大的资源浪费。
所以协调好处理流量洪峰和资源利用率,最好的方式就是设计错峰方案进行流量削峰。
削峰目的:
让服务处理请求更加平缓,节省服务器资源。
针对于削峰来说,本质上是延缓用户请求的发送,减少和过滤一些无效请求。
一般采用以下方式:
- 排队
- 答题
- 分层过滤
这几种方案都是无损的,当然有损的方案如限流,负载保护等,是另一种不得已的措施,以后再谈。
排队
流量削峰首先想到的就是队列,将同步的请求转换成异步请求,将流量峰值通过消息队列平缓推送过去。
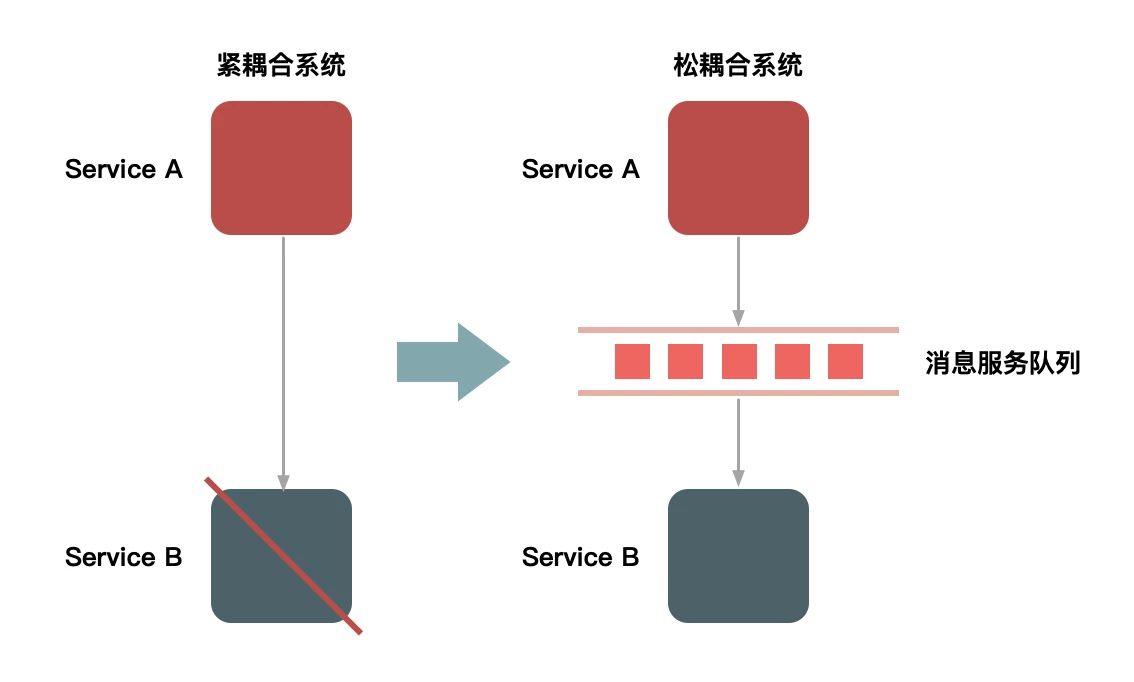
当然消息队列需要注意的是消息挤压和存储上限等情况。
类似的排队方式还有很多,如:
- 线程池加锁
- 先进先出内存队列
- 类似于binlog的顺序写读处理的机制
答题
一般的电商系统秒杀时会有一个答题流程,主要是为了增加购买的复杂度,首先可以防止一些机器参与秒杀的场景,起到防止作弊的目的。还可以拉大请求时间缓解请求,控制流量达到削峰的目的。
由于经过答题之后的请求具有了先后顺序,这样对于后续的业务逻辑来说就可以很容易的控制了。
答题逻辑的设计:
- 题库产生,生成一个个的问题和答案,问题也不用特别复杂,可以防止机器作弊即可。
- 题库推送,在秒杀进行之前,将问题推送给交易系统。
- 问题图片生成,用于将题目生成制定格式图片,增加一些干扰因素,问题图片可以提前推送到cdn进行预热,不然在真正秒杀开始时,可能图片加载缓慢影响用户体验。
答题逻辑比较简单了,用户提交答案,后台比对题目和答案即可。 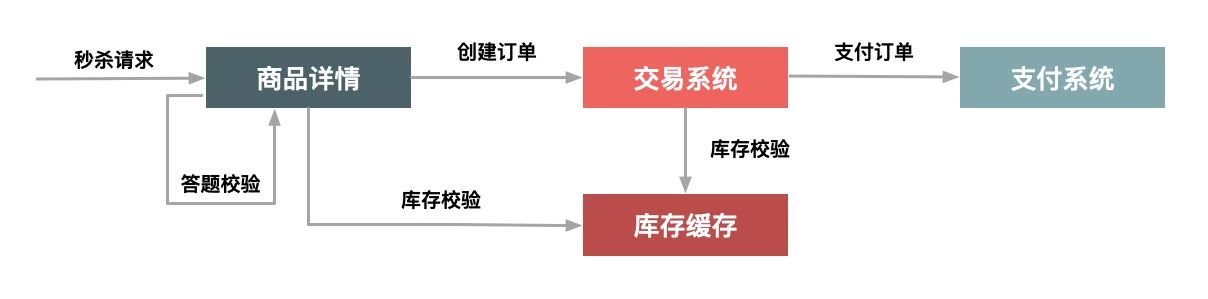
分层过滤
针对于秒杀场景来说,跟本质的做法是过滤无效请求,分层过滤是采用漏斗方式进行请求处理的。 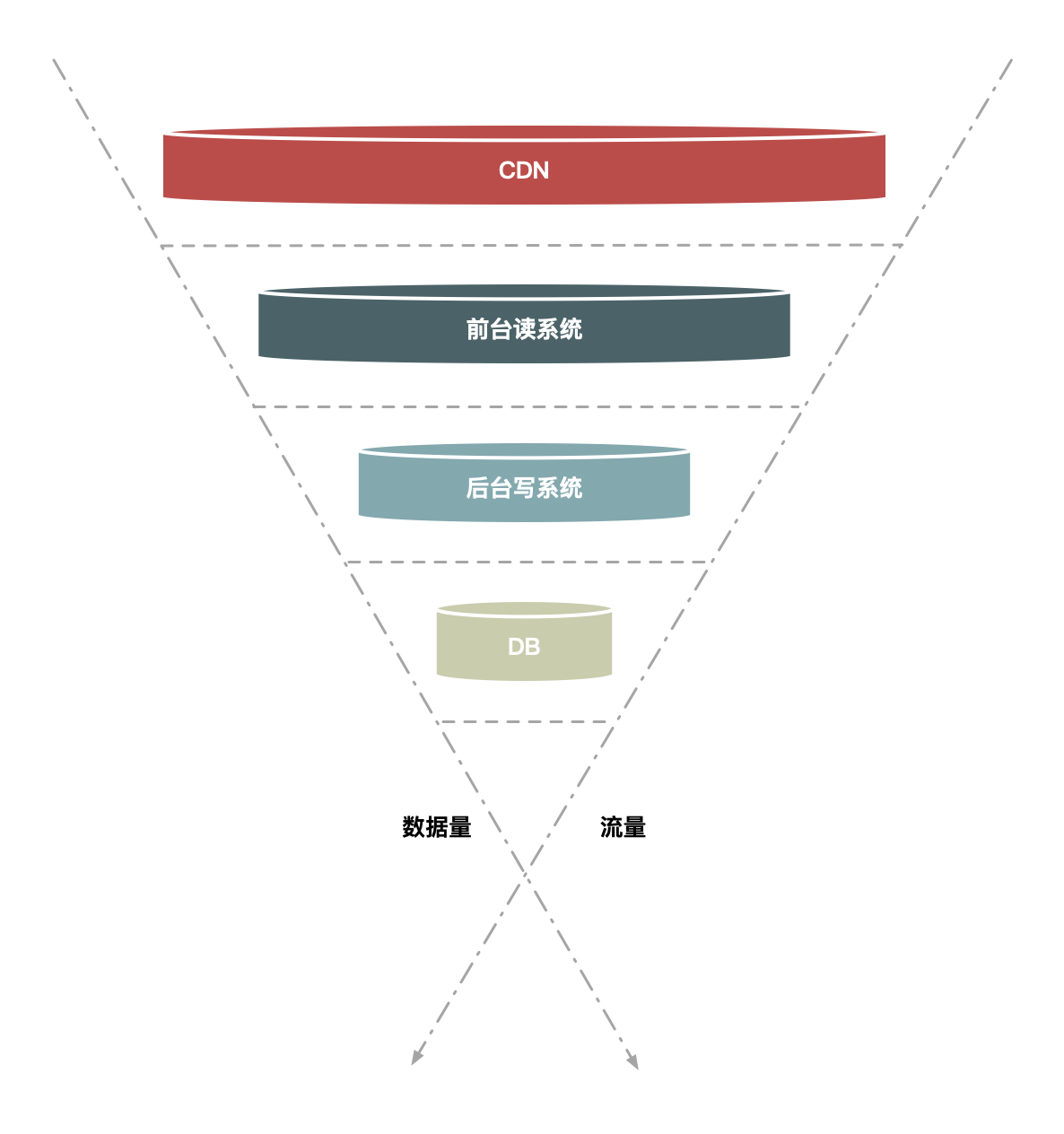
请求流程:
- 大部分流量在用户浏览器或者cdn上获取,这一层可以拦截大量数据读取。
- 前台读系统主要是一些缓存cache,比如采用nginx+lua等方式拦截无效请求。
- 业务系统主要做好限流,排队等操作。对数据做合理分片。
- 在最后的数据层做好数据强一致校验,比如保证库存的准确性(不能为负数)。
这样请求经过一层层的漏斗过滤,会尽量将少的数据请求到后端了。
